|
|
< Previous | Next > |
| Product: Volume Manager Guides | |
| Manual: Volume Manager 4.1 Administrator's Guide | |
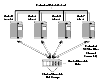
Overview of Cluster Volume ManagementIn recent years, tightly coupled cluster systems have become increasingly popular in the realm of enterprise-scale mission-critical data processing. The primary advantage of clusters is protection against hardware failure. Should the primary node fail or otherwise become unavailable, applications can continue to run by transferring their execution to standby nodes in the cluster. This ability to provide continuous availability of service by switching to redundant hardware is commonly termed failover. Another major advantage of clustered systems is their ability to reduce contention for system resources caused by activities such as backup, decision support and report generation. Businesses can derive enhanced value from their investment in cluster systems by performing such operations on lightly loaded nodes in the cluster rather than on the heavily loaded nodes that answer requests for service. This ability to perform some operations on the lightly loaded nodes is commonly termed load balancing. The cluster functionality of VxVM works together with the cluster monitor daemon that is provided by VCS or by the host operating system. When configured correctly, the cluster monitor informs VxVM of changes in cluster membership. Each node starts up independently and has its own cluster monitor plus its own copies of the operating system and VxVM with support for cluster functionality. When a node joins a cluster, it gains access to shared disk groups and volumes. When a node leaves a cluster, it no longer has access to these shared objects. A node joins a cluster when the cluster monitor is started on that node. Example of a 4-Node Cluster illustrates a simple cluster arrangement consisting of four nodes with similar or identical hardware characteristics (CPUs, RAM and host adapters), and configured with identical software (including the operating system). The nodes are fully connected by a private network and they are also separately connected to shared external storage (either disk arrays or JBODs: just a bunch of disks) via SCSI or Fibre Channel. The private network allows the nodes to share information about system resources and about each other's state. Using the private network, any node can recognize which other nodes are currently active, which are joining or leaving the cluster, and which have failed. The private network requires at least two communication channels to provide redundancy against one of the channels failing. If only one channel were used, its failure would be indistinguishable from node failure---a condition known as network partitioning.
Click the thumbnail above to view full-sized image. To the cluster monitor, all nodes are the same. VxVM objects configured within shared disk groups can potentially be accessed by all nodes that join the cluster. However, the cluster functionality of VxVM requires that one node act as the master node; all other nodes in the cluster are slave nodes. Any node is capable of being the master node, and it is responsible for coordinating certain VxVM activities. VxVM determines that the first node to join a cluster performs the function of master node. If the master node leaves a cluster, one of the slave nodes is chosen to be the new master. In Example of a 4-Node Cluster, node 0 is the master node and nodes 1, 2 and 3 are slave nodes. Private and Shared Disk GroupsTwo types of disk groups are defined:
In a cluster, most disk groups are shared. Disks in a shared disk group are accessible from all nodes in a cluster, allowing applications on multiple cluster nodes to simultaneously access the same disk. A volume in a shared disk group can be simultaneously accessed by more than one node in the cluster, subject to licensing and disk group activation mode restrictions. You can use the vxdg command to designate a disk group as cluster-shareable as described in Importing Disk Groups as Shared. When a disk group is imported as cluster-shareable for one node, each disk header is marked with the cluster ID. As each node subsequently joins the cluster, it recognizes the disk group as being cluster-shareable and imports it. As system administrator, you can also import or deport a shared disk group at any time; the operation takes place in a distributed fashion on all nodes. Each physical disk is marked with a unique disk ID. When cluster functionality for VxVM starts on the master, it imports all shared disk groups (except for any that have the noautoimport attribute set). When a slave tries to join a cluster, the master sends it a list of the disk IDs that it has imported, and the slave checks to see if it can access them all. If the slave cannot access one of the listed disks, it abandons its attempt to join the cluster. If it can access all of the listed disks, it imports the same shared disk groups as the master and joins the cluster. When a node leaves the cluster, it deports all its imported shared disk groups, but they remain imported on the surviving nodes. Reconfiguring a shared disk group is performed with the cooperation of all nodes. Configuration changes to the disk group happen simultaneously on all nodes and the changes are identical. Such changes are atomic in nature, which means that they either occur simultaneously on all nodes or not at all. Whether all members of the cluster have simultaneous read and write access to a cluster-shareable disk group depends on its activation mode setting as discussed in Activation Modes of Shared Disk Groups. The data contained in a cluster-shareable disk group is available as long as at least one node is active in the cluster. The failure of a cluster node does not affect access by the remaining active nodes. Regardless of which node accesses a cluster-shareable disk group, the configuration of the disk group looks the same. Activation Modes of Shared Disk GroupsA shared disk group must be activated on a node in order for the volumes in the disk group to become accessible for application I/O from that node. The ability of applications to read from or to write to volumes is dictated by the activation mode of a shared disk group. Valid activation modes for a shared disk group are exclusive-write, read-only, shared-read, shared-write, and off (inactive). These activation modes are described in detail in the table Activation Modes for Shared Disk Groups.
Special uses of clusters, such as high availability (HA) applications and off-host backup, can use disk group activation to explicitly control volume access from different nodes in the cluster. Activation Modes for Shared Disk Groups
The following table summarizes the allowed and conflicting activation modes for shared disk groups: Allowed and Conflicting Activation Modes
Shared disk groups can be automatically activated in any mode during disk group creation or during manual or auto-import. To control auto-activation of shared disk groups, the defaults file /etc/default/vxdg must be created. The defaults file /etc/default/vxdg must contain the following lines: enable_activation=true default_activation_mode=activation-mode The activation-mode is one of exclusive-write, read-only, shared-read, shared-write, or off. When a shared disk group is created or imported, it is activated in the specified mode. When a node joins the cluster, all shared disk groups accessible from the node are activated in the specified mode. If the defaults file is edited while the vxconfigd daemon is already running, the vxconfigd process must be restarted for the changes in the defaults file to take effect. If the default activation mode is anything other than off, an activation following a cluster join, or a disk group creation or import can fail if another node in the cluster has activated the disk group in a conflicting mode. To display the activation mode for a shared disk group, use the vxdg list diskgroup command as described in Listing Shared Disk Groups. You can also use the vxdg command to change the activation mode on a shared disk group as described in Changing the Activation Mode on a Shared Disk Group. For a description of how to configure a volume so that it can only be opened by a single node in a cluster, see Creating Volumes with Exclusive Open Access by a Node and Setting Exclusive Open Access to a Volume by a Node. Connectivity Policy of Shared Disk GroupsA shared disk group provides concurrent read and write access to the volumes that it contains for all nodes in a cluster. A shared disk group can only be created on the master node. This has the following advantages and implications:
The practical implication of this design is that I/O failure on any node results in the configuration of all nodes being changed. This is known as the global detach policy. However, in some cases, it is not desirable to have all nodes react in this way to I/O failure. To address this, an alternate way of responding to I/O failures, known as the local detach policy, was introduced in release 3.2 of VxVM. The local detach policy is intended for use with shared mirrored volumes in a cluster. This policy prevents I/O failure on a single slave node from causing a plex to be detached. This would require the plex to be resynchronized when it is subsequently reattached. The local detach policy is available for disk groups that have a version number of 70 or greater. The detach policies have no effect if the master node loses access to all copies of the configuration database and logs in a disk group. If this happened in releases prior to 4.1, the master node always disabled the disk group. Release 4.1 introduces the disk group failure policy, which allows you to change this behavior for critical disk groups. This policy is only available for disk groups that have a version number of 120 or greater. The following sections describe the detach and failure policies in greater detail. Global Detach PolicyThe global detach policy is the traditional and default policy for all nodes on the configuration. If there is a read or write I/O failure on a slave node, the master node performs the usual I/O recovery operations to repair the failure, and the plex is detached cluster-wide. All nodes remain in the cluster and continue to perform I/O, but the redundancy of the mirrors is reduced. When the problem that caused the I/O failure has been corrected, the mirrors that were detached must be recovered before the redundancy of the data can be restored. Local Detach PolicyThe local detach policy is designed to support failover applications in large clusters where the redundancy of the volume is more important than the number of nodes that can access the volume. If there is a write failure on a slave node, the master node performs the usual I/O recovery operations to repair the failure, and additionally contacts all the nodes to see if the disk is still acceptable to them. If the write failure is not seen by all the nodes, I/O is stopped for the node that first saw the failure, and the application using the volume is also notified about the failure. If required, configure the cluster management software to move the application to a different node, and/or remove the node that saw the failure from the cluster. The volume continues to return write errors, as long as one mirror of the volume has an error. The volume continues to satisfy read requests as long as one good plex is available. If the reason for the I/O error is corrected and the node is still a member of the cluster, it can resume performing I/O from/to the volume without affecting the redundancy of the data. See Setting the DIsk Detach Policy on a Shared Disk Group for information on how to use the vxdg command to set the disk detach policy on a shared disk group.
The table, Cluster Behavior Under I/O Failure to a Mirrored Volume for Different Disk Detach Policies,summarizes the effect on a cluster of I/O failure to the disks in a mirrored volume: Cluster Behavior Under I/O Failure to a Mirrored Volume for Different Disk Detach Policies
Disk Group Failure Policy
The local detach policy by itself is insufficient to determine the desired behavior if the master node loses access to all disks that contain copies of the configuration database and logs. In this case, the disk group is disabled. As a result, the other nodes in the cluster also lose access to the volume. In release 4.1, the disk group failure policy is introduced to determine the behavior of the master node in such cases. This policy has two possible settings as shown in the following table: Behavior of Master Node for Different Failure Policies
The behavior of the master node under the disk group failure policy is independent of the setting of the disk detach policy. If the disk group failure policy is set to leave, all nodes panic in the unlikely case that none of them can access the log copies. See Setting the Disk Group Failure Policy on a Shared Disk Group for information on how to use the vxdg command to set the failure policy on a shared disk group. Guidelines for Choosing Detach and Failure PoliciesIn most cases it is recommended that you use the global detach policy, and particularly if any of the following conditions apply:
The local detach policy may be suitable in the following cases:
If you have a critical disk group that you do not want to become disabled in the case that the master node loses access to the copies of the logs, set the disk group failure policy to leave. This prevents I/O failure on the master node disabling the disk group. However, critical applications running on the master node fail if they lose access to the other shared disk groups. In such a case, it may be preferable to set the policy to dgdisable, and to allow the disk group to be disabled. The default settings for the detach and failure policies are global and dgdisable respectively. You can use the vxdg command to change both the detach and failure policies on a shared disk group, as shown in this example: # vxdg -g diskgroup set diskdetpolicy=local dgfailpolicy=leave Effect of Disk Connectivity on Cluster ReconfigurationThe detach policy, previous I/O errors, or access to disks are not considered when a new master node is chosen. When the master node leaves a cluster, the node that takes over as master of the cluster may already have seen I/O failures for one or more disks. Under the local detach policy, only one node was affected before reconfiguration, but when the node becomes the master, the failure is treated as described in Effect of Disk Connectivity on Cluster Reconfiguration. The detach policy does not change the requirement that a node joining a cluster must have access to all the disks in all shared disk groups. Similarly, a node that is removed from the cluster because of an I/O failure cannot rejoin the cluster until this requirement is met. Limitations of Shared Disk GroupsOnly raw device access may be performed via the cluster functionality of VxVM. It does not support shared access to file systems in shared volumes unless the appropriate software is installed and configured. The cluster functionality of VxVM does not support RAID-5 volumes, or task monitoring for cluster-shareable disk groups. These features can, however, be used in private disk groups that are attached to specific nodes of a cluster. If you have RAID-5 volumes in a private disk group that you wish to make shareable, you must first relayout the volumes as a supported volume type such as stripe-mirror or mirror-stripe. Online relayout of shared volumes is supported provided that it does not involve RAID-5 volumes. If a shared disk group contains RAID-5 volumes, deport it and then reimport the disk group as private on one of the cluster nodes. Reorganize the volumes into layouts that are supported for shared disk groups, and then deport and reimport the disk group as shared. |
|||||||||||||||||||||||||||||||||
| ^ Return to Top | < Previous | Next > |
| Product: Volume Manager Guides | |
| Manual: Volume Manager 4.1 Administrator's Guide | |
|
VERITAS Software Corporation
www.veritas.com |